Understanding Bias and Variance in Machine Learning Models
Written on
Chapter 1: Introduction to Bias and Variance
As the use of machine learning expands across various domains, the scrutiny on machine learning algorithms has intensified. The complexity of developing and assessing ML models has grown due to larger datasets, diverse implementations, and specific learning requirements. Each of these elements significantly affects the model's accuracy and learning results, complicating matters further with false assumptions, noise, and outliers.
To ensure that machine learning models are reliable, users must have a deep understanding of their data and the algorithms employed. Any flaws in the algorithm or contamination in the dataset can adversely affect the performance of the model. This article delves into bias and variance within machine learning, highlighting their implications for the reliability of these models.
Section 1.1: Defining Bias in Machine Learning
Bias represents a systematic deviation in algorithmic outcomes, favoring or opposing certain ideas. It arises from incorrect assumptions made during the machine learning process. In technical terms, bias can be described as the discrepancy between the average predictions of the model and the actual outcomes. It illustrates how well the model corresponds with the training dataset: a model with significant bias fails to align closely with the data, while a model with low bias closely mirrors it.
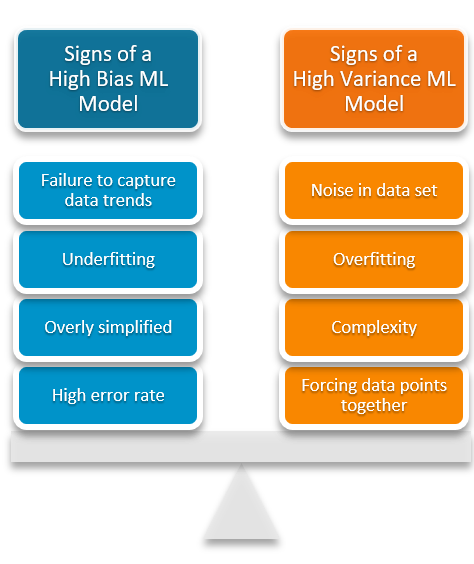
Characteristics of a model with high bias include:
- Inability to capture essential data patterns
- Tendency towards underfitting
- Overly generalized or simplistic outputs
- Elevated error rates
Section 1.2: Understanding Variance in Machine Learning
Variance pertains to the fluctuations in model performance when utilizing different subsets of the training dataset. In simpler terms, it refers to the model's sensitivity to the training data—how much the predictions can shift based on the specific data provided. Typically, models with high bias display low variance, whereas those with high variance tend to have low bias.
These dynamics influence the overall flexibility of the model. For example, a model that fails to align with a dataset due to high bias will be rigid and have low variance, ultimately resulting in an ineffective machine learning model.
Characteristics of a model with high variance include:
- Presence of noise in the dataset
- Propensity for overfitting
- Complexity in model design
- Attempts to fit all data points as closely as possible
- Issues related to both underfitting and overfitting
The concepts of underfitting and overfitting describe how well a model correlates with the data. Underfitting occurs when the model lacks the complexity to match the training data accurately, leading to poor performance. Conversely, overfitting occurs when the model attempts to conform to patterns in the training data that do not exist, resulting in high accuracy during training but poor generalization to new data.
Chapter 2: The Bias-Variance Trade-off
Bias and variance are inversely related; it is impossible to construct a machine learning model that simultaneously exhibits low bias and low variance. When a data engineer refines an algorithm for better alignment with a dataset, it typically reduces bias but increases variance. This trade-off means the model may fit the training data well, yet increase the risk of inaccurate predictions.
The opposite holds true for models with low variance and high bias. Although this setup minimizes the chances of prediction errors, it compromises the model's ability to accurately reflect the dataset.
Finding the right balance between bias and variance is crucial. Notably, higher variance does not automatically signify a poor machine learning algorithm, as algorithms should be able to accommodate a reasonable degree of variance.
Strategies to address this trade-off include:
- Enhancing model complexity to mitigate bias and variance, which helps align the model with the training dataset without introducing excessive variance errors.
- Expanding the training dataset, particularly beneficial for overfitting scenarios, allows for increased complexity without the risk of variance errors affecting the model.
A larger dataset provides more data points, facilitating better generalization by the algorithm. However, the challenge with increasing the training dataset is that low bias models may not respond sensitively to variations in the data. Thus, enlarging the dataset is an effective approach for managing high variance and high bias models.
Considering Bias and Variance: A Necessity
When developing accurate machine learning models, it is vital to consider both bias and variance. Bias leads to consistent errors, resulting in simpler models that may not meet specific requirements. In contrast, variance introduces variability that can lead to inaccurate predictions by misinterpreting nonexistent trends.
Users must take both factors into account when designing an ML model. Ideally, the goal is to minimize bias while allowing for acceptable levels of variance, which can be achieved through increased model complexity or expanded training datasets.
By maintaining this balance, one can develop a robust machine learning model that performs effectively.
In Plain English?
Thank you for being part of the In Plain English community! Before you go, don't forget to clap and follow the writer.
Follow us on: X | LinkedIn | YouTube | Discord | Newsletter
Explore our other platforms: Stackademic | CoFeed | Venture | Cubed
For more content, visit PlainEnglish.io
The first video, "How to check your unconscious bias - Dr Jennifer Eberhardt | Global Goals," delves into understanding and addressing unconscious biases that may affect decision-making processes.
The second video, "Understanding unconscious bias | The Royal Society," provides insights into the nature of unconscious bias and its implications in various fields.