Innovative Solutions for Building LLM-Powered Applications
Written on
Understanding Common Challenges in LLM Development
Large language models (LLMs), such as GPT, have ignited a new wave of technological advancements. Entrepreneurs and product developers are eager to incorporate these models into their offerings or create entirely new products. However, crafting AI applications that leverage LLMs isn't as simple as engaging in conversation with ChatGPT. Numerous challenges may arise during development, and this article aims to highlight some of the most significant hurdles encountered while deploying LLM-backed applications.
In this discussion, we will examine prevalent issues faced during the development of products utilizing LLMs and explore potential solutions based on extensive research. Key topics include managing intra-conversation and short-term memory for chatbots, long-term memory utilizing vector databases (chunking, embedding, and retrieval for question answering), output formatting to optimize token usage, caching LLM responses for scalability, and local deployment of LLMs. This article will delve into technical aspects, so prepare for an in-depth exploration!
Common Issues and Solutions in LLM Applications
(Note: This article assumes a fundamental understanding of ChatGPT and language models. If a refresher is needed, consider reading: How ChatGPT works, explained for non-technical audiences.)
Managing Intra-Conversation/Short-Term Memory
With the emergence of ChatGPT as a chatbot, natural interaction has gained renewed interest. Many companies and enthusiasts are attempting to create their own chatbots based on the GPT API. A primary challenge in this endeavor is managing intra-conversation memory, which refers to the history and short-term context of the conversation between the user and the LLM. This is crucial, as the GPT API does not maintain stateful memory of the entire dialogue.
A straightforward solution might be to store every message in a variable and return it to the API with each interaction. This approach, known as buffering, involves saving and relaying previous messages. However, as conversations lengthen, it becomes impractical to send all messages due to the LLM's context limit (e.g., GPT-3.5 has a 3000-token threshold).
An enhancement to this method is buffer window memory, akin to ChatGPT's approach—discarding messages that fall outside the context window size, whether by message count or token limit. However, this could lead to the omission of earlier information during the conversation.
example_prompt_with_context = """
You're a helpful assistant. You will help the user complete their request.
The following is a conversation between you and the user.
{conversation_context}
User: Explain ChatGPT to me.
AI:
"""
An alternative solution involves summarization, where previous messages are condensed into a summary and utilized as context for ongoing dialogue. This could be achieved by sending a prompt to the LLM to summarize prior messages at each turn or after a set number of exchanges. Incremental summarization can also be applied by appending only new message summaries to existing ones. Combining summarization with buffering can further enhance context retention.
Additionally, consider using different data structures to preserve key information during conversations instead of merely tracking the dialogue. For instance, entity memory can be established by creating a dictionary of entities and their actions, such as people, objects, places, and events discussed during the interaction. A separate prompt can be employed to extract pertinent data from the LLM during the conversation. Similarly, constructing a knowledge graph memory to document entities, their attributes, and relationships is also feasible.
entity_memory_example = {
'entities': {
'Luna': 'Luna is eating her breakfast in the kitchen.',
'Fiona': 'Fiona sees Luna in the kitchen and initiates a conversation.'
}
}
Long-Term Memory with Vector Databases
For those looking to retain information across multiple interactions or utilize a substantial amount of pre-existing data for document-based question answering, vector databases are an ideal solution. This section will outline the fundamental process of integrating LLMs with vector databases, including data preparation for storage (chunking strategies), embedding techniques, available vector databases, retrieval strategies, and methods for enhancing retrieval quality and speed.
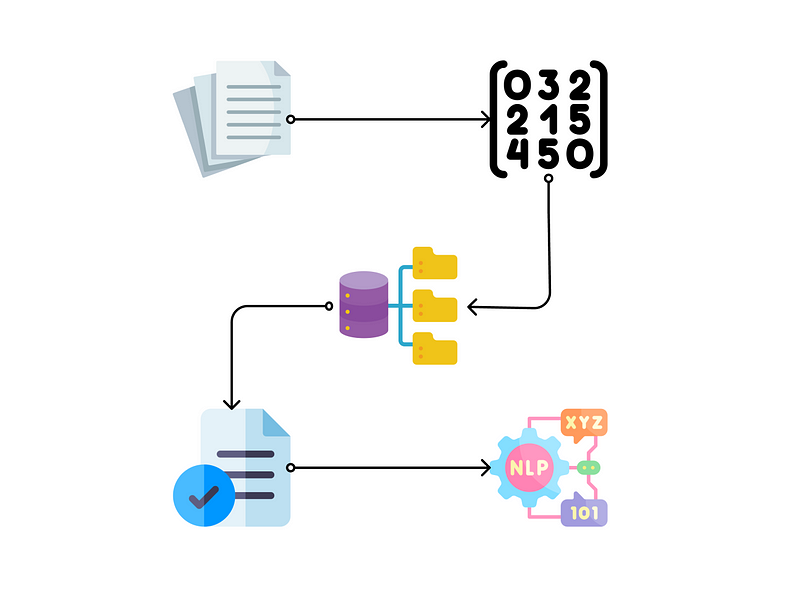
Understanding the Chunking Process
The initial step in this process is to break down lengthy documents into smaller, manageable pieces. Various chunking strategies exist, and here are some guidelines to assist in determining the most suitable approach:
- Fit the Context Window: Since LLMs often have context window limits on prompt length, ensure chunks are smaller than this threshold to effectively combine them with the user's prompt as context.
- Consider User Queries: If users typically ask specific questions requiring concise answers, shorter chunks may be more effective. Conversely, longer questions that necessitate broader context may benefit from larger chunks.
- Match Query Length and Complexity: Align chunk sizes with the expected length and complexity of user questions.
- Maintain Coherence: If original documents contain coherent paragraphs that explain singular ideas, avoid breaking them apart. Conversely, if multiple connected ideas exist, consider chunking them together.
Based on these guidelines, select a chunking method appropriate for your use case, such as fixed-size by tokens, sentence-based splitting, overlapping chunking, recursive chunking, or document format-based chunking. Most of these methods are supported by LangChain, but more complex formats may require custom implementation.
Embedding Document Chunks
Once documents are appropriately chunked, the next step is embedding them into high-dimensional vector representations. Various embedding methods are available, such as:
- Flair: Contextualized embeddings, though slower.
- SpaCy: Faster pre-trained embeddings based on transformer architectures like BERT.
- FastText: Pre-trained on web content, capable of handling out-of-vocabulary words.
- SentenceTransformers: Specifically for sentence embeddings based on BERT.
- Commercial APIs: OpenAI's Ada, Amazon SageMaker, and Hugging Face Embeddings are good options.
Selecting the right embedding method depends on factors like document size, text type, and accuracy requirements.
Choosing the Right Vector Database
Now that documents have been converted into embeddings, storing them in a vector database for future retrieval is the next step. Vector databases are optimized for storing high-dimensional data, facilitating efficient retrieval and processing compared to traditional databases.
Popular options include:
- Pinecone: Fully-managed vector database with extensive documentation.
- Milvus: One of the pioneering open-source vector databases.
- Weaviate: Another open-source vector database.
- Chroma: Open-source under the Apache 2.0 license, supporting Python and JavaScript.
- Qdrant: Managed vector database with user-friendly APIs.
Choosing between self-hosting a vector database or utilizing a managed service depends on your project's complexity, security, and scalability needs.
Retrieval Techniques
When users submit a query, it's necessary to retrieve the most relevant chunks from the vector database. Most databases utilize a K-Nearest Neighbors (KNN) algorithm to identify the most similar chunks to the query based on similarity metrics.
While ideally, only the most relevant chunk is needed, this is often not the case. Therefore, various strategies must be employed to retrieve the necessary chunks and incorporate them into prompts. LangChain supports several methods, including:
- Stuffing: Directly input all relevant chunks into the prompt. This method is simple but limited by the LLM's context window.
- Map-Reduce: Retrieve the top relevant chunks, query each one, and combine the responses. This method is beneficial for summarization but may result in some loss of information.
- Refine: Generate an answer based on the first chunk and iteratively improve it using subsequent chunks. This approach is advantageous when combining information from multiple sources.
- Map Rerank: Generate answers for each chunk with a certainty score, ranking them to determine the most reliable response.
Enhancing Retrieval Quality
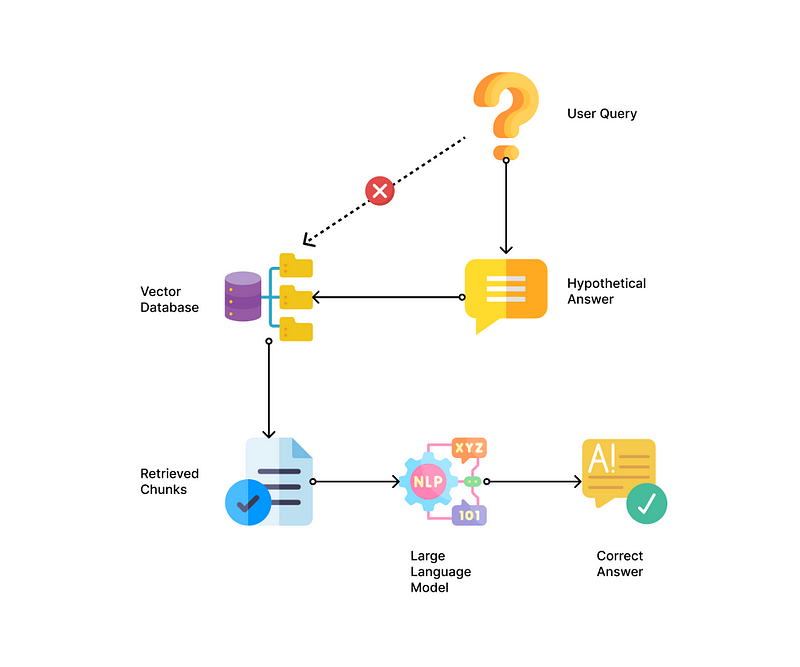
To improve retrieval outcomes, especially when user queries differ significantly in vocabulary from the content, consider generating a hypothetical answer with the LLM, then comparing the embeddings of this "fake answer" against the chunks in the database. This approach, known as Hypothetical Document Embeddings (HyDE), has shown promising results.
Formatting Outputs for Efficiency
When integrating LLMs into products, controlling output format can be crucial. Due to the inherent variability in transformer-based models, responses may differ in structure. Specifying a desired format in the system role can enhance consistency, though some formats may consume more tokens.
Nikas Praninskas conducted an experiment comparing data formats for token efficiency, revealing that:
- Minimized JSON: More efficient than standard JSON, but challenging to enforce.
- YAML or TOML: Effective for nested datasets, saving 25-50% compared to JSON.
- CSV: Suitable for flat data but inefficient for nested structures.
Caching LLM Responses for Scalability
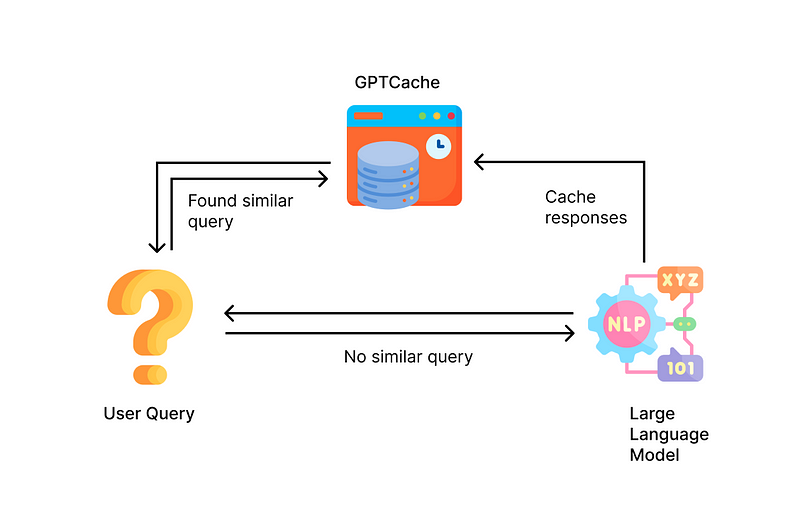
For applications serving large user bases, scalability and cost-efficiency are paramount. Traditional applications often utilize in-memory caching solutions like Redis to enhance performance. For LLMs, a similar concept applies, but the implementation varies.
Instead of sending every request to the LLM API, caching responses can help manage costs and improve performance. A new library, GPTCache, has been developed to facilitate this process, using embeddings to determine query similarities and optimize response retrieval.
Local Deployment of LLMs
The GPT API from OpenAI imposes various limitations, including rate limits and data processing constraints. Deploying an LLM locally can alleviate these issues, providing greater control over data and ensuring sensitive information remains within the organization's infrastructure.
Fortunately, the open-source community has made significant strides in developing alternatives to GPT that can be hosted on-premises. Notable options include:
- Dolly V2: Developed by Databricks, based on the EleutherAI Pythia model.
- GPT4All-J: A version of GPT-J utilizing LoRA fine-tuning, featuring a one-click installer.
- Cerebras-GPT: A series of models based on GPT-3 architecture.
- Flan Family: Including Flan-T5 and Flan-UL2 from Google.
- StableLM: Developed by StabilityAI, the creators of Stable Diffusion.
While these models may not match GPT's size and capabilities, they can effectively handle tasks like simple conversations and document-based question answering.
Conclusion
Congratulations on reaching the end! Developing AI applications with LLMs presents numerous opportunities for innovation, alongside various challenges to navigate during productization and implementation. This article aims to clarify some of the obstacles you may encounter while creating LLM-powered products. Stay informed, and happy developing!
If you're interested in understanding and creating your own autonomous agents similar to AutoGPT, consider exploring a comprehensive guide to autonomous agents with GPT.
References & Links:
In the video "Build your own LLM Apps with LangChain & GPT-Index," viewers will learn how to create applications leveraging LangChain and GPT-Index, exploring practical implementations and examples.
The video titled "LangChain Complete Tutorial, Part 1" provides an in-depth introduction to LangChain, covering fundamental concepts and practical applications for developers looking to harness the power of LLMs.