Creating Art with AI: The VQGAN + CLIP Revolution
Written on
Chapter 1: The Impact of AI on Artistic Expression
For centuries, art has epitomized human creativity and imagination. From the iconic Mona Lisa by Leonardo da Vinci to the mesmerizing Starry Night by Vincent van Gogh, artistic talent has long been viewed as a hallmark of human intelligence. Yet, with the rise of artificial intelligence (AI), we may be witnessing a significant shift in this narrative. AI technologies can now produce novels, articles, music, and artworks, although they often fall short of the depth found in creations by skilled artists and writers. Nevertheless, some AI-generated pieces can be surprisingly captivating.

When I prompted an AI model to envision “A dramatic mountainous landscape on fire by Ivan Aivazovsky,” it delivered an interpretation that, while reminiscent of his style, lacked coherence and detail in various aspects. The question arises: what if AI-produced literature, music, and art were to meet the standards of the Turing Test?
The Turing Test, originally named the Imitation Game by Alan Turing in the 1950s, assesses whether a machine can exhibit intelligent behavior indistinguishable from that of a human. This raises profound questions about the future of human creativity and the very definition of art. Although the outcomes remain uncertain, I can certainly guide you on using AI to create art.
The artwork showcased above was generated using a publicly available AI model known as VQGAN + CLIP. In the following sections, we will explore how to utilize VQGAN + CLIP to produce art without requiring any coding skills while also touching upon the underlying deep learning technologies involved.
Chapter 2: Generating Art with VQGAN + CLIP
Using VQGAN + CLIP on Google Colab, I was able to effortlessly generate AI art by simply entering text prompts like “a song of ice and fire by Greg Rutkowski, matte painting” and clicking a button. YouTuber The A.I. Whisperer provides an excellent step-by-step tutorial on employing VQGAN + CLIP via Google Colab.
This video provides a quick overview of how to create art using VQGAN + CLIP, making it accessible for beginners.
Choosing effective text prompts is crucial for generating compelling art. The process of systematically selecting the best prompts for achieving a desired style is referred to as prompt engineering. For instance, we can instruct the AI to render an image in the style of a specific artist by appending “by [artist’s name]” to our image description. Including descriptive adjectives like “epic,” “magnificent,” or “beautiful” can also enhance the outcome. Additionally, the artistic style can be specified using terms like “oil painting” or “watercolor,” with commas separating them from the main description. However, this process often involves a degree of experimentation.
Generating art through this method can be computationally intensive. Consequently, many users opt for cloud computing platforms like Google Colab rather than running these AI models on personal devices. Google Colab allows users to execute AI code on powerful remote servers, significantly reducing the time required to create art by utilizing CUDA for GPU parallel processing.
CUDA, or Compute Unified Device Architecture, is a software framework developed by Nvidia that enables GPUs to perform general-purpose calculations similar to CPUs. GPUs are generally more efficient for training and running AI algorithms due to their ability to handle multiple calculations simultaneously, thanks to a greater number of processing cores.
Chapter 3: Understanding the VQGAN + CLIP Framework
VQGAN + CLIP was developed by Katherine Crowson (@RiversHaveWings) and Ryan Murdoch (@advadnoun) and gained popularity through Google Colab in early 2021. As the name suggests, it combines two AI models: Vector Quantised Generative Adversarial Network (VQGAN) and Contrastive Language-Image Pre-training (CLIP). In essence, VQGAN serves as the “generator,” while CLIP functions as the “perceptor.” This partnership allows VQGAN to create images based on text prompts, while CLIP assesses how closely the generated images align with the descriptions using a metric known as loss. A smaller loss indicates a closer match between the image and the textual description, prompting VQGAN to adjust its output in response to CLIP’s feedback.
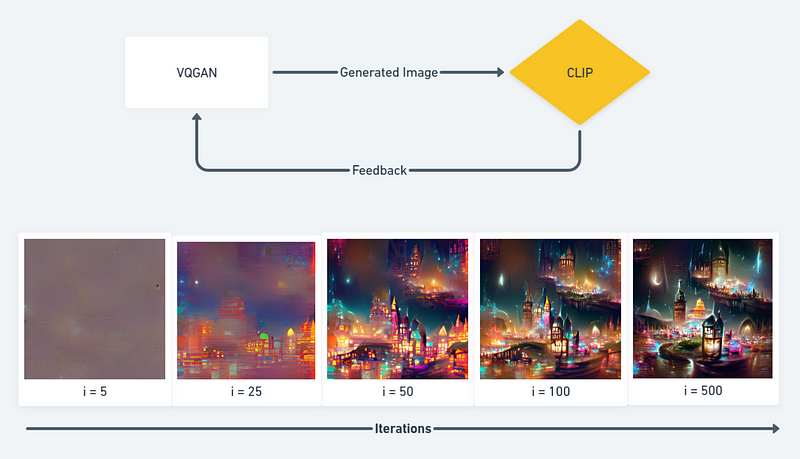
Each iteration involves generating an image, which is then evaluated by CLIP, and the feedback is relayed back to VQGAN. Over successive iterations, the produced image increasingly aligns with the text prompt. For instance, when using the prompt “A magical city at night, trending on Artstation,” the generated image improves with each cycle.
Delving into the technical intricacies of VQGAN and CLIP can quickly become complex. However, if you're interested in a more detailed exploration, Lj Miranda offers an informative blog post on the subject.
If you enjoyed this article, consider showing your support with claps or tips. Follow my work for more insights, as I aim to publish content monthly. For further reading and references, please check the following resources.
This video showcases how you can create art using just one sentence, demonstrating the capabilities of AI in generating visuals with minimal input.