Exploring the Advantages of Modularity and Sparsity in DNNs
Written on
Chapter 1: Understanding Deep Neural Networks
Deep neural networks (DNNs) have increasingly drawn inspiration from human cognitive processes. Recent advancements demonstrate how incorporating modular structures and attention mechanisms can enhance these networks. By organizing knowledge modularly and utilizing attention to select pertinent information, DNN models can establish significant inductive biases, improve their ability to generalize beyond training data, and engage with concepts at a higher cognitive level.
This paragraph will result in an indented block of text, typically used for quoting other text.
Section 1.1: The Challenge of Assessing Modularity
Despite the established benefits of modular architectures for DNNs, there is currently no robust quantitative assessment approach for these systems. The complexity and unpredictable nature of real-world data distributions make it challenging to ascertain whether performance improvements in modular systems stem from effective architecture design.
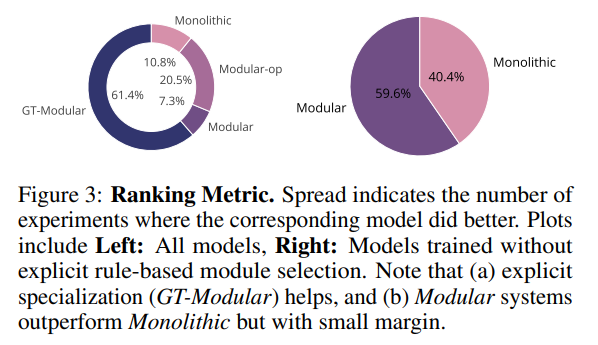
Subsection 1.1.1: Research Insights
In their recent publication titled "Is a Modular Architecture Enough," a research team from Mila and the Université de Montréal undertakes a comprehensive quantitative evaluation of prevalent modular architectures. Their findings illuminate the advantages of both modularity and sparsity for DNNs, and point out the limitations of current end-to-end learned modular systems.

The researchers summarize their key contributions as follows: “We create benchmark tasks and metrics using probabilistically selected rules to quantify two vital aspects of modular systems: the degree of collapse and specialization. We analyze commonly adopted modularity inductive biases through a series of models designed to extract typical architectural attributes (Monolithic, Modular, Modular-op, and GT-Modular models). Our results indicate that specialization within modular systems significantly enhances performance when multiple underlying rules are present but shows less impact when few rules are utilized. Additionally, we find that standard modular systems often perform sub-optimally in focusing on relevant information and in their specialization abilities, indicating a need for further inductive biases.”

Section 1.2: Types of Models Analyzed
The team examines four different model types, each with varying levels of specialization: Monolithic (a large neural network processing all input data), Modular (multiple modules, each a neural network processing data), Modular-op (similar to modular but with activation determined solely by rule context), and GT-Modular (an idealized modular system representing perfect specialization). They conduct a detailed analysis of the advantages of each system, comparing simple end-to-end trained modular systems with monolithic architectures.
Chapter 2: Performance Evaluation
The research includes an exploration of both in-distribution and out-of-distribution performance, assessing how different models perform across various tasks. They also introduce two new metrics—Collapse-Avg and Collapse-Worst—to evaluate the level of collapse experienced by a modular system, alongside metrics for alignment, adaptation, and inverse mutual information to measure specialization.

In the conducted experiments, the GT-Modular system consistently exhibited the highest performance, affirming the benefits of achieving perfect specialization. While standard end-to-end trained modular systems showed slight advantages over monolithic systems, the reliance on backpropagation of task losses limits their ability to discover optimal specialization.
Both Modular and Modular-op systems demonstrated issues with collapse, though Modular-op typically experienced fewer problems. The researchers propose that investigating more regularization methods may help mitigate these collapse issues.
Overall, this study demonstrates that modular models tend to outperform monolithic ones. While modular networks can achieve perfectly specialized solutions, end-to-end training does not fully recover these capabilities, indicating that additional inductive biases are essential for learning adequately specialized solutions. The authors hope their findings will inspire future research focused on designing and developing modular architectures.
Open-sourced implementation is available on the project's GitHub. The paper "Is a Modular Architecture Enough?" can be found on arXiv.
We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
In this video, Yoshua Bengio discusses the transition from System 1 to System 2 deep learning, shedding light on the intricacies of modular architectures and their implications in AI research.
This presentation by Yoshua Bengio at NeurIPS 2019 further explores the shift from System 1 to System 2 deep learning, emphasizing the role of modularity in advancing deep neural networks.